
Medien-Tracking mit Github und YAML
Über den Blogbeitrag von Katy Decorah bin ich auf die Idee gestossen, Medientracking in einfachen YAML-Files auf Github laufen zu lassen.
Was sind die Vorteile?
Github-Content liegt gespiegelt lokal auf meiner Festplatte. Alle Inhalte sind versioniert, d.h. ich kann jederzeit einen alten Stand wiederherstellen. YAML ist einerseits ein maschinenlesbares Datenformat, im Gegensatz zu JSON aber auch mit meinen immer schlechter werdenden Gleitsichtaugen relativ einfach les- und verstehbar. Ein automatisches Skript kann daran genauso gut Änderungen vornehmen, wie ich im Editor.
Und wie sieht das aus?
In meinem Repository liegen in einem Unter-Ordner die folgenden YAML Files. Damit tracke ich Bücher, Serien und Filme, die ich geschaut oder gelesen habe (oder noch lesen will).
Ein Eintrag sieht dann z.B. so aus:

Das ist natürlich noch nicht so richtig schön anzuschauen. Dafür nutze ich dann Github-Pages. Das ist vereinfacht gesagt ein Feature, bei dem mit ein bisschen Konfiguration und Magie aus den YAML Files am Ende eine Webseite mit hübschem Frontend rauspurzelt. Wenn alles mal eingerichtet ist, passiert das automatisch. D.h. jedes Mal, wenn ich an einer der YAML Dateien etwas ändere und z.B. einen neuen Film hinzufüge, wird die Webseite neu erstellt.
Die Seite mit meinem Medientracking findet man dann unter heibie.github.io/media-archive
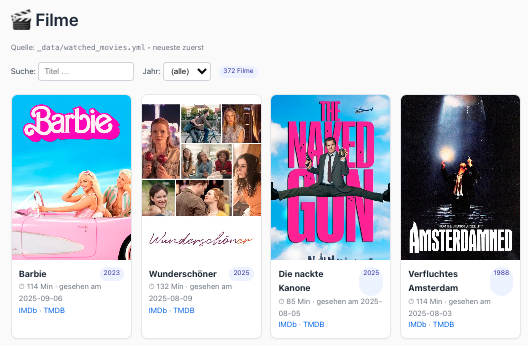
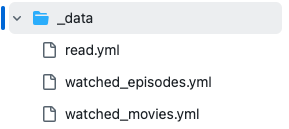
Ich hab mir eine Einstiegsseite gebaut, auf der die neuesten Einträge gelistet werden. Über die Navigation kommt man zu den einzelnen Medientypen und kann weiter browsen.
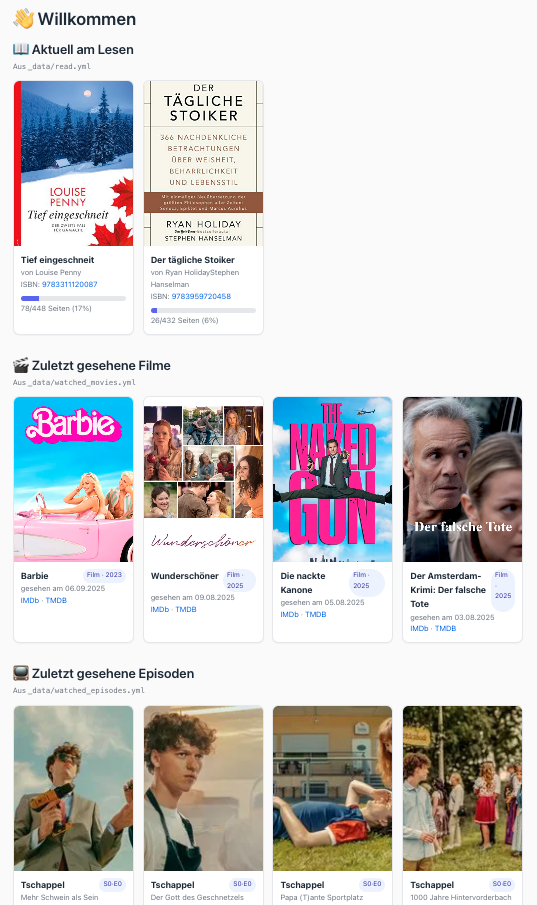
Bei den Büchern lasse ich mir den Lesefortschritt anzeigen ...
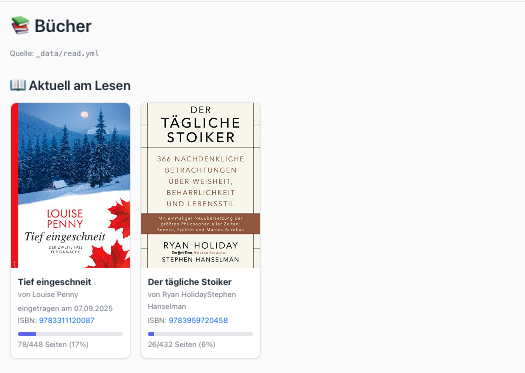
... bookmarke mir, was ich vielleicht mal lesen will ...
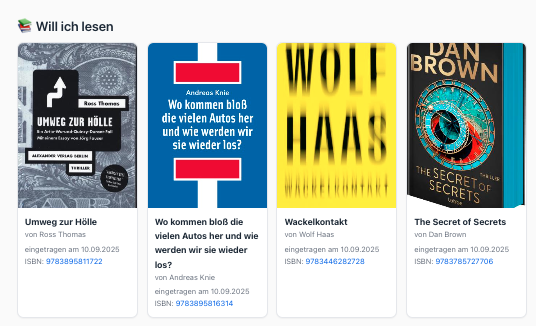
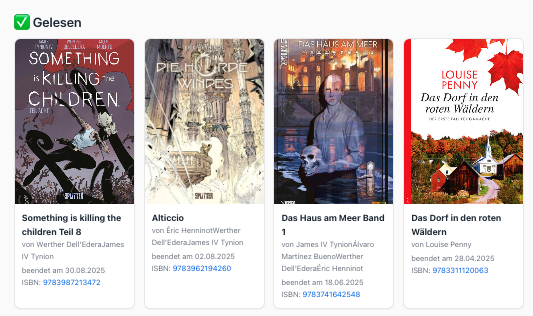
... und was ich gelesen habe.
Bei den Filmen werden einfach chronologisch die letzten Check-ins gelistet.
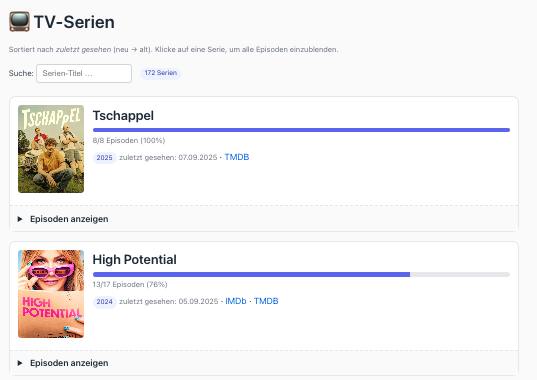
Und bei den Serien die zuletzt geschauten Episoden und dazu noch wieviel Episoden übrig sind.
Wo kommen die ganzen Daten überhaupt her?
Ich tracke seit 2015 alle Filme und Serien, die ich schaue. Zuerst mit der IMDB-App. Daraus hab ich mir dann immer ein CSV exportiert und in ein Google-Sheet importiert. Vor ein paar Monaten habe ich mithilfe von ChatGPT alles zu trakt.tv migriert. Mit Trakt.tv bin ich ziemlich zufrieden. Es findet auch viele deutsche TV-Inhalte zuverlässig und die Bedienung ist intuitiv.
Bei den Büchern habe ich nicht ganz so konsequent bei goodreads getrackt und dann noch an einer anderen Stelle, wo ich beruflich Rezensionen verfasse.
Für mein neues Tracking musste ich die Daten erst mal alle zusammenfügen.
Die Filme und Serien lassen sich bei trakt.tv sehr gut strukturiert als JSON exportieren. Das lässt sich mit einem einfachen Skript leicht in YAML konvertieren.
Bei den Büchern war das wegen der beiden unterschiedlichen Quellen etwas umständlicher, aber ein paar Scraping und Importskripte später habe ich da jetzt auch einen soliden Stand auf dem ich weiter arbeiten kann.
Wie werden die Daten eingepflegt?
Bei den Büchern habe ich erst mal einen Github-Action-Workflow, bei dem ich die ISBN eingebe und ein Script dann automatisch alle fehlenden Informationen zusammensucht und ins YAML einträgt. Das ist nicht superkomfortabel, aber ich aktualisiere da auch nicht ständig neue Einträge.
Filme und Serien checke ich weiterhin bei trakt.tv ein, weil es mit der App am schnellsten geht. Ein Skript holt dann automatisch neue Einträge ab und trägt sie in die YAML-Dateien ein.
Wie lange hat das alles gedauert?
Ich hab nichts davon selbst gecodet. Ich habe ein grundsätzliches technisches Verständnis für das, was da passiert und was ich erreichen will, der Code kommt aus ChatGPT. Insgesamt war das deutlich aufwändiger und langwieriger als das WordPress-Plugin. ChatGPT hat vor allem bei dem Scraping und Importsachen zuerst immer Fehler produziert und es brauchte einiges Sparring bis wir gemeinsam zum gewünschten Ergebnis gekommen sind. Außerdem wird Web-ChatGPT bei der immer wieder korrigierten Code-Erstellung mit der Zeit langsamer, der Chat unbenutzbar. Ich musste während des ganzen Prozesses immer wieder neue Chats aufmachen, die ich in einem Projekt gruppiert habe. ChatGPT merkt sich dadurch leichter den Kontext, wenn man nach einem Tag wieder neu einsteigt, aber manchmal war es trotzdem nötig den zuletzt erarbeiteten Code-Stand noch mal mitzuteilen.
Warum machst du das überhaupt?
Über die Faszination des (Medien)-Trackings schreibe ich vielleicht mal einen eigenen Blogbeitrag. Ich mache das jedenfalls schon lange und war mit der technischen Umsetzung nie so richtig zufrieden. Mein kleines minimalistisches Medienarchiv, dass ich zur Not in jedem beliebigen Texteditor unabhängig pflegen kann gefällt mir schon in diesem sehr frühen Beta-Stadium supergut und ich habe tausend Ideen, wie das erweitert werden kann.
Kommentare (10)
Reposts (3)
Likes (3)
Kommentare (2)
Bin beeindruckt. Ich tracke meinen Medienkonsum tatsächlich ganz billig in der Notizen App auf iPhone und iPad. Das ist natürlich furchtbar unübersichtlich, aber immerhin gibt es eine Suchfunktion, um mein größtes Problem zu lösen: „Hm, der Film kommt mir verdammt bekannt vor, hab ich den etwa schon mal gesehen …?“
[…] hab mir mit KI gerade einen neuen Media-Tracker gebaut. Im Social Media Watchblog gibt es viele Praxistipps zum Umgang mit KI. Eine Quelle wiederum für […]
Antworten (2)
Friedrich Merz und der Sozialstaat: Man muss es nicht Klassenkampf nennen (€) „Jedes Mal, wenn eine Wahl in einem ostdeutschen Bundesland ansteht, deren erschreckende Ergebnisse…
Nach Filmen, Serien und Büchern hab ich mein Medientracking jetzt erweitert. Ich scrobble seit 2011 meine gestreamte Musik zu last.fm. Ich glaube am Anfang war…
Kommentar schreiben